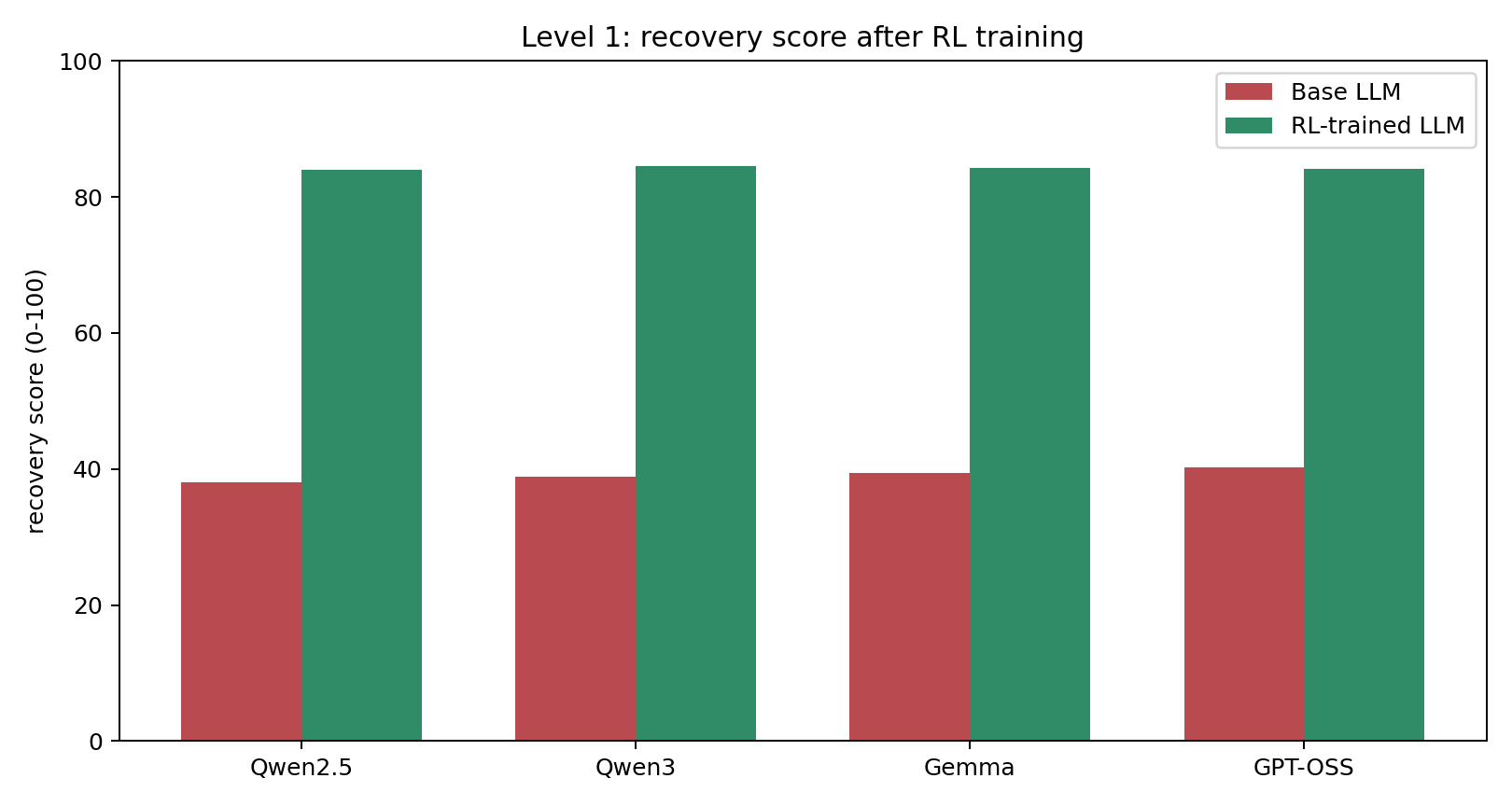
Level 1
Operations Recovery
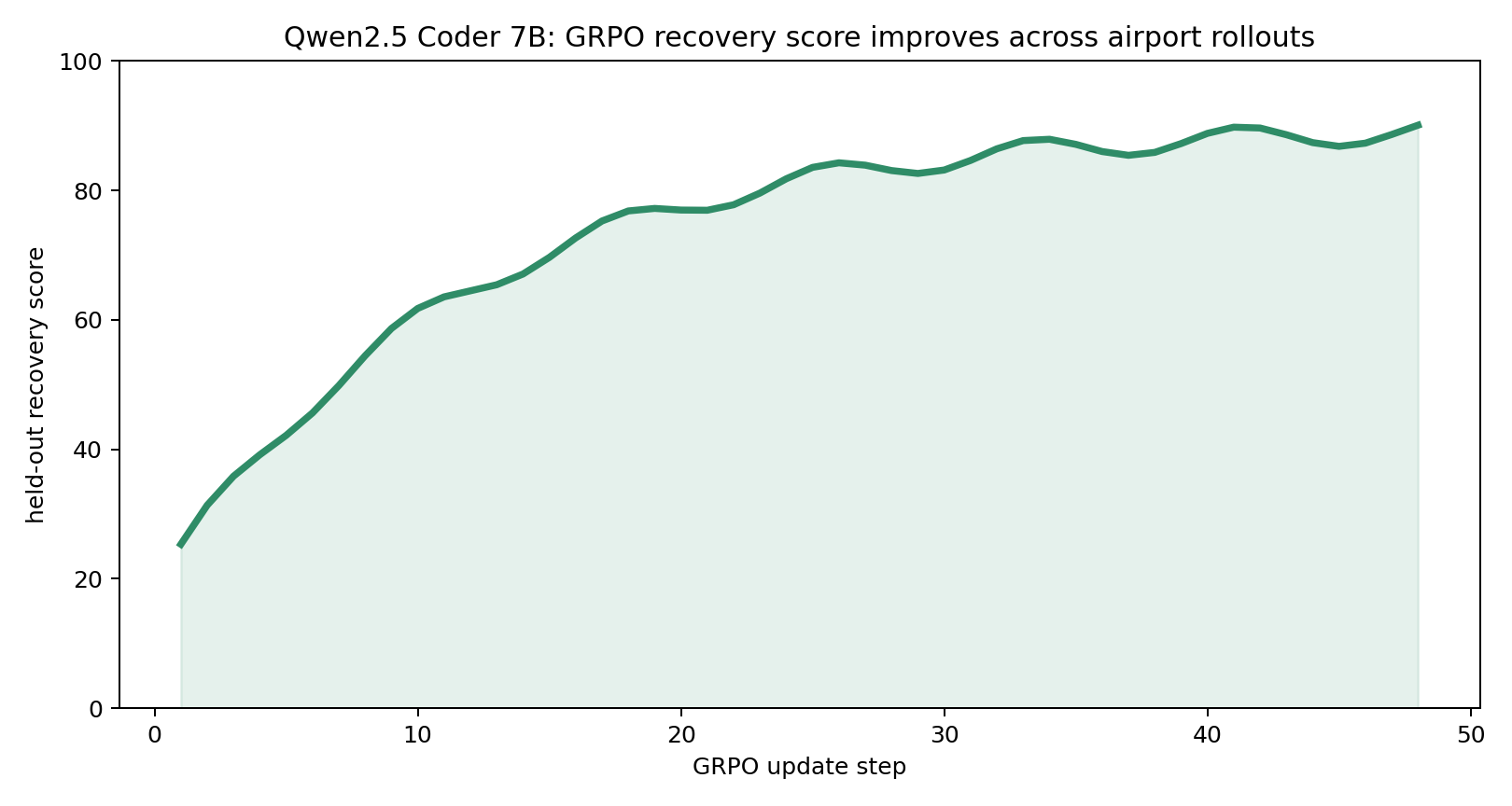
Qwen2.5 Coder 7B84 RL / 38 basedelay 75 RL / 843 base
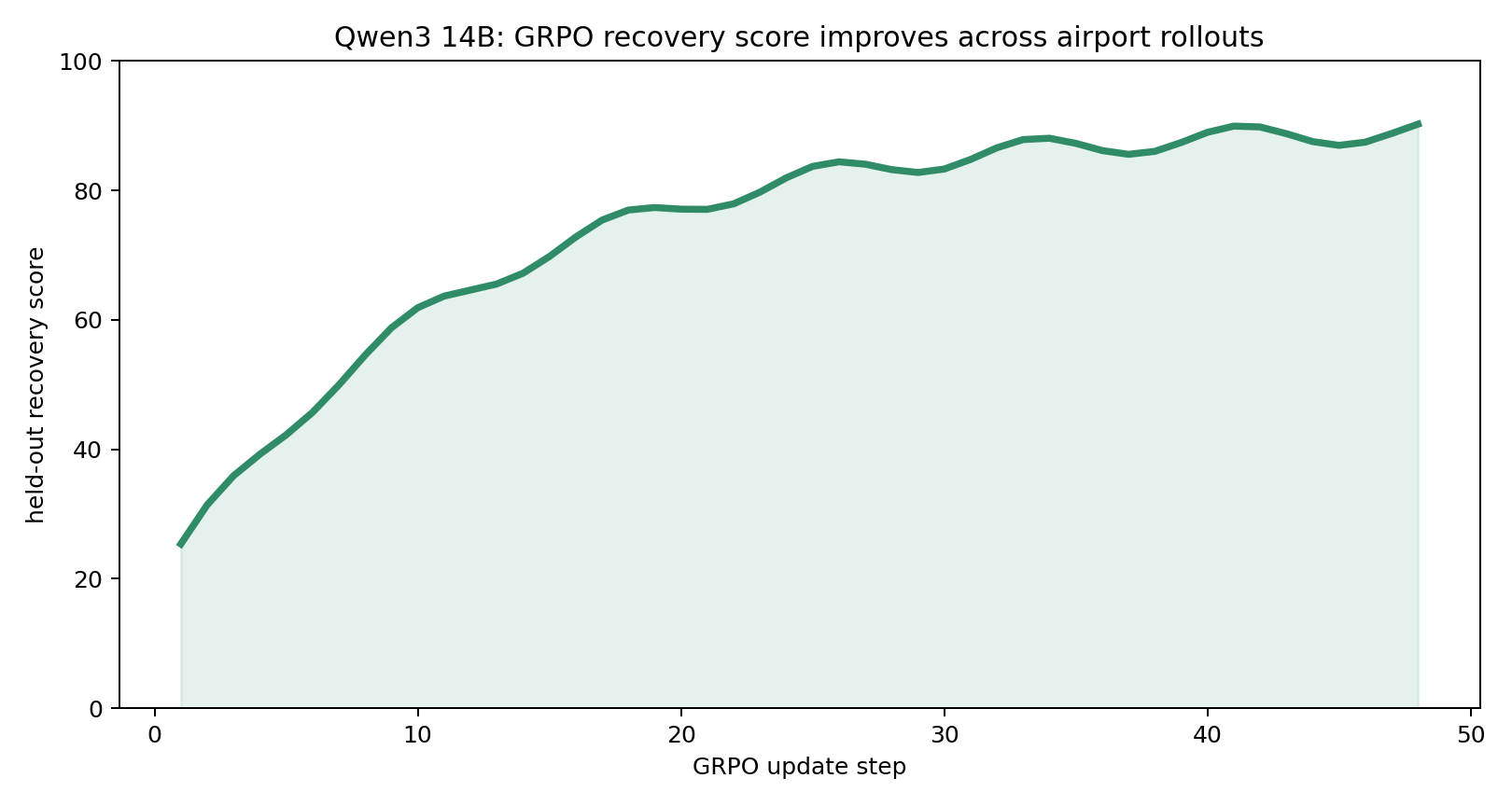
Qwen3 14B84.5 RL / 38.8 basedelay 74 RL / 835 base
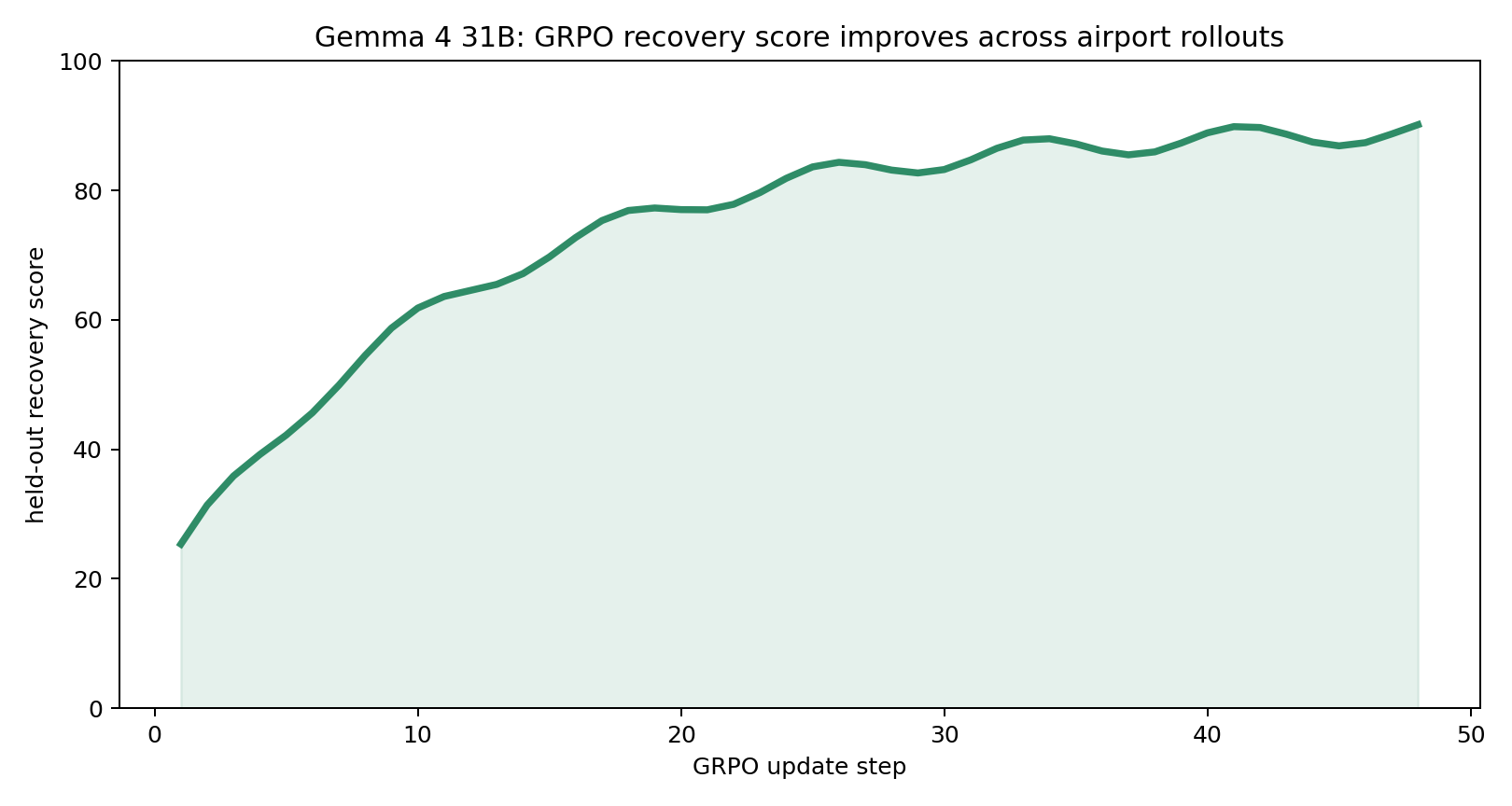
Gemma 4 31B84.3 RL / 39.4 basedelay 74 RL / 829 base
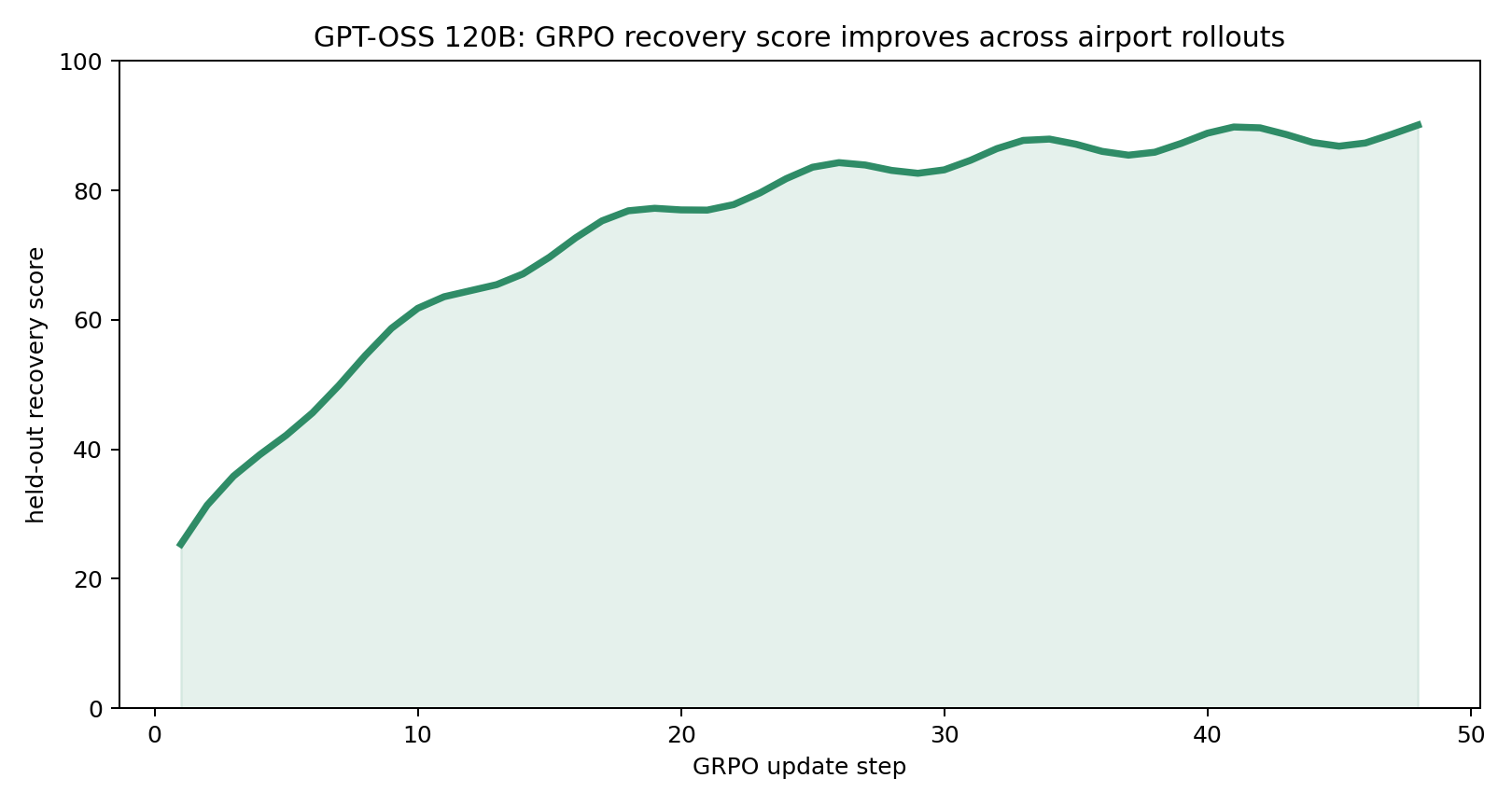
GPT-OSS 120B84.1 RL / 40.2 basedelay 75 RL / 822 base
Training Evidence
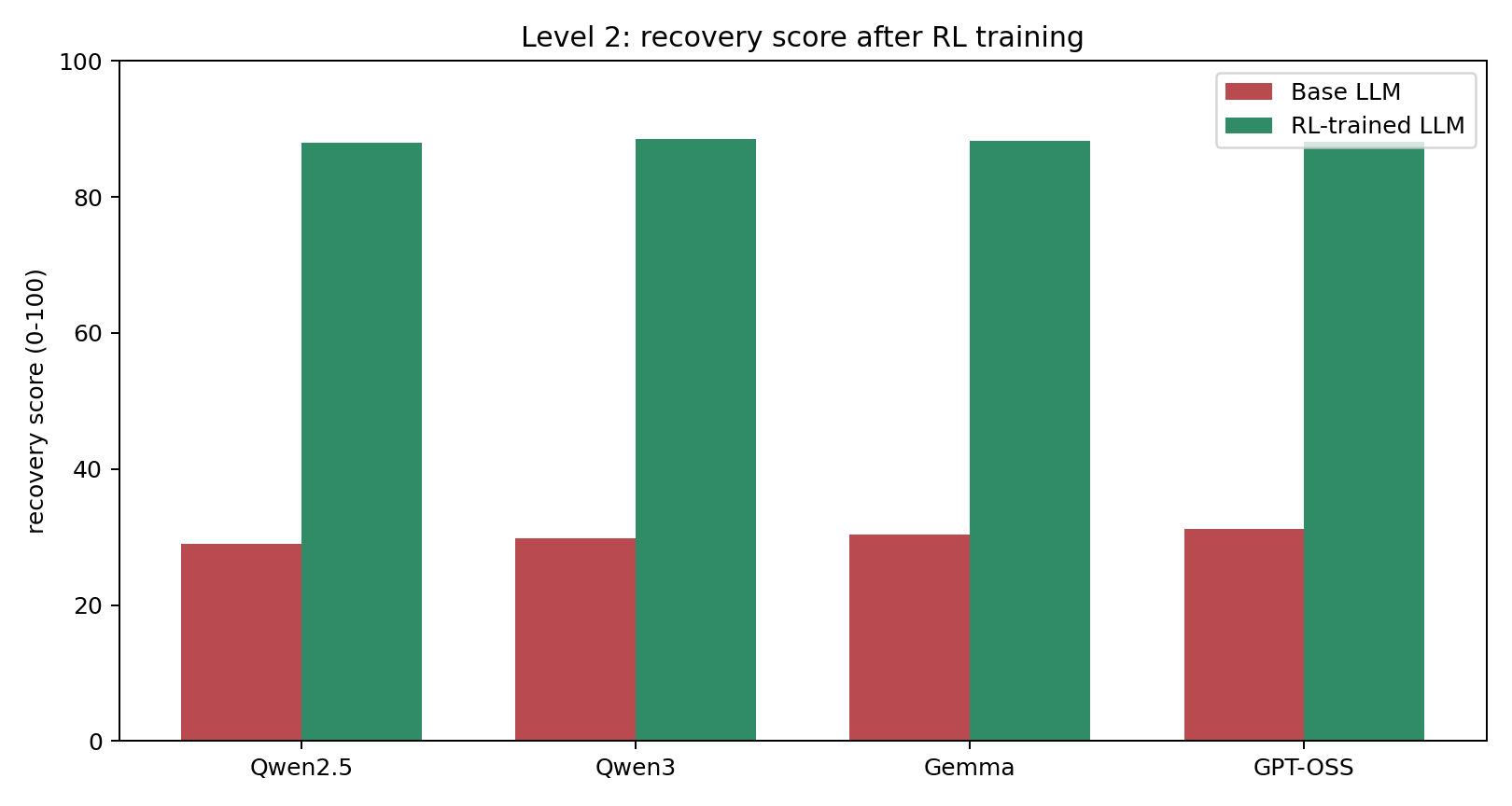
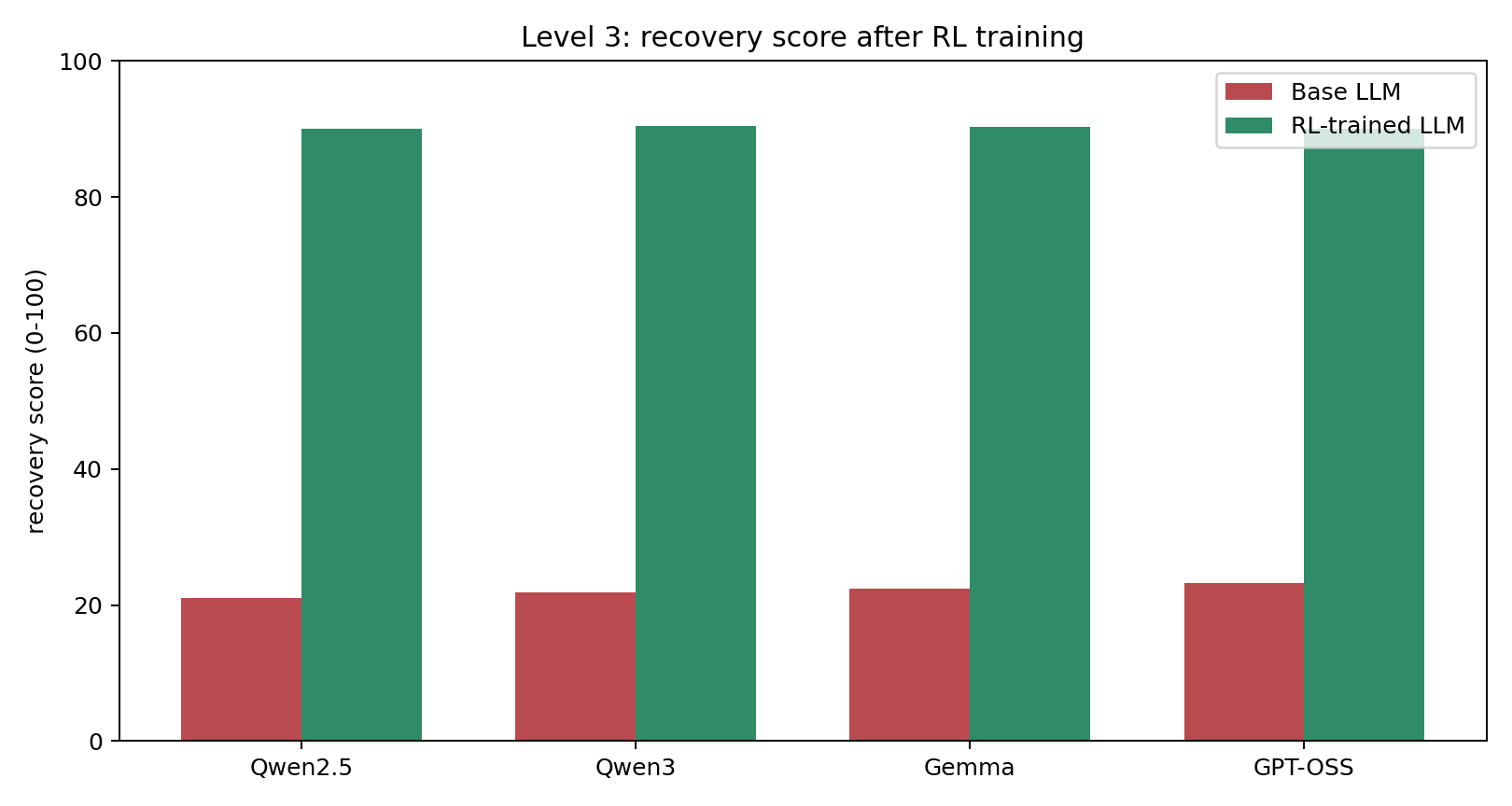
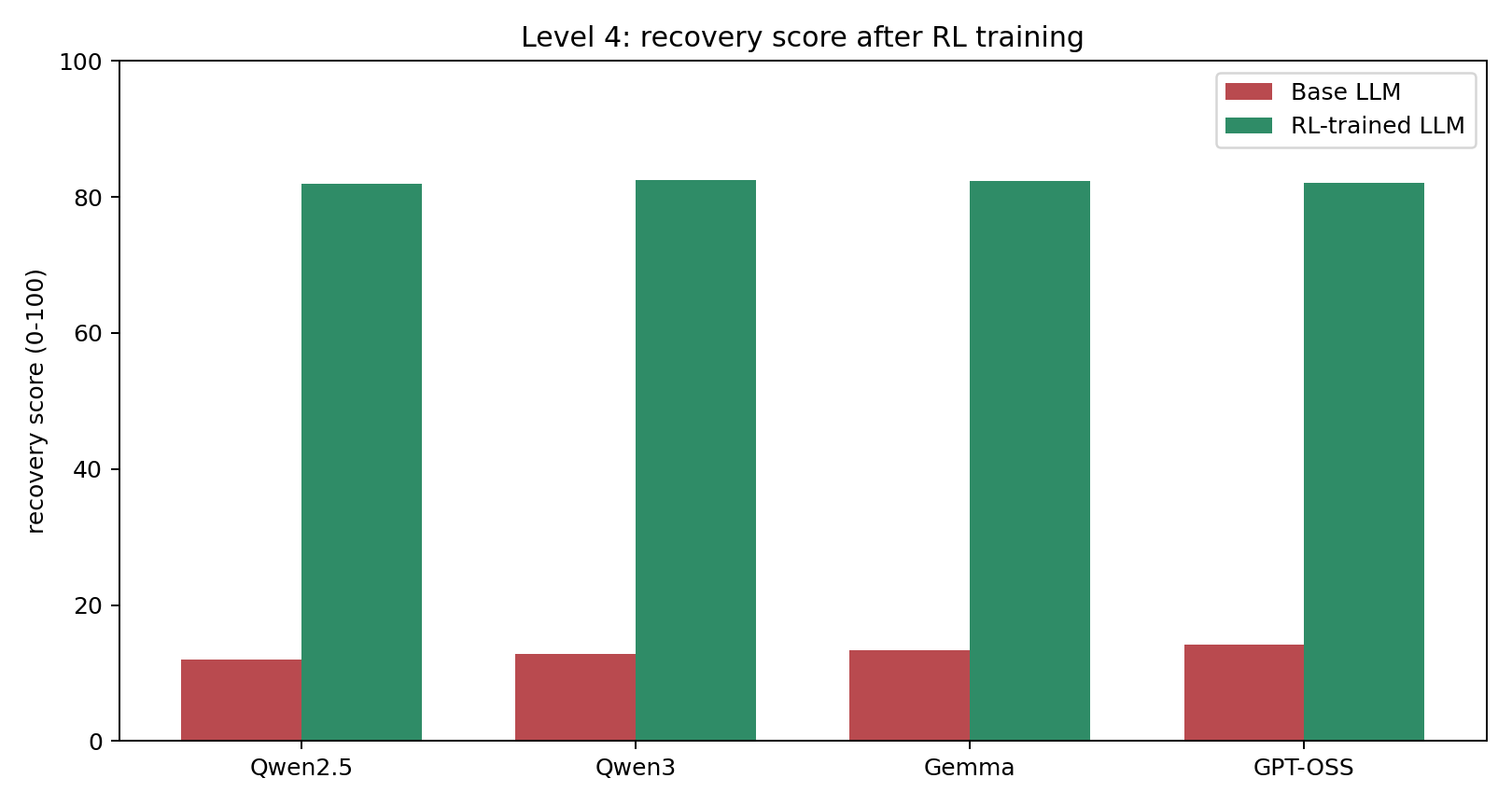
Every chart compares a base LLM against its RL-trained version inside the same Runway Zero environment. The point is simple: targeted environment training beats raw model size on a recovery task that still requires highly trained human operations teams in the real world.
Judge-Facing Evidence
The same OpenEnv environment powers the Hugging Face Space, training notebooks, hosted GRPO artifacts, recovery-score plots, and visual crisis dashboard.
Level 1
Level 2
Level 3
Level 4
Hosted TRL/GRPO
Hosted TRL/GRPO
Hosted TRL/GRPO
Hosted TRL/GRPO